
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- suninatas
- UKPT level
- 연구모임
- 파이썬
- 국가정보원
- 화학물질
- Los
- 프로젝트
- 국정원
- Service
- PHP
- 국가기록원
- 화학물질불법유통온라인감시단
- UKPT
- nurisec
- 도구모음
- 화학물질안전원
- 웹 해킹 입문
- 정보보안
- 불법유통근절
- 대외활동
- 12기
- MITRE ATT&CK
- webhacking
- 기타정보
- 불법유통
- codeup
- HTML
- 여행
- 경기팀
Archives
- Today
- Total
agencies
CVE 검색 및 파싱 본문
오늘은 특정 키워드를 CVE 홈페이지에 검색하고,
도출된 검색 결과를 가져오는 파이썬 프로그래밍을 진행했습니다.
※ pip 설치 내용
1. selenium
2. beautifulsoup4
3. requests
소스코드
#버전 0.1
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
import re
import requests
# cve 검색
test = input("keyword: ")
# version 검색
version = input("version: ")
# ChromeOptions
chrome_options = Options()
#chrome_options.add_argument('--headless') # 브라우저 UI 없이 실행
chrome_options.add_argument('--disable-gpu') # GPU 사용 비활성화
# 웹 드라이버 객체 생성 + 10초 대기
driver = webdriver.Chrome(options=chrome_options)
driver.implicitly_wait(10)
# exploit-db URL
url = 'https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword='+test
driver.get(url)
#robots
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"}
try:
# 검색바 요소 찾기
time.sleep(1)
#search_box = driver.find_element(By.CSS_SELECTOR, 'input[type="search"]')
# 페이지의 HTML 콘텐츠
time.sleep(1)
page_source = driver.page_source
# BeautifulSoup을 사용하여 페이지 파싱
soup = BeautifulSoup(page_source, 'html.parser')
rows = soup.find_all('tr')
cvenum = []
cvedes = []
for row in rows:
cve_num = row.find('a')
#cve 찾기
if cve_num and 'CVE-' in cve_num.get_text(strip=True):
#print(cve_num.get_text(strip=True))
cvenum.append(cve_num.get_text(strip=True))
#print("=========================================")
# 해당 행의 두 번째 <td>를 찾아 설명 추출
description_td = row.find_all('td')[1] # 두 번째 <td> 찾기
description_text = description_td.get_text(strip=True)
cvedes.append(description_text)
#print("=========================================")
# 버전 정보를 정규 표현식으로 추출
versions = re.findall(r'\b(?!(?:\d{4,}))(?:\d+)(?:\.\d+)*(?:\.x)?\b', description_text)
if versions:
print(f"CVE Number: {cve_num.get_text(strip=True)}")
#print(f"Description: {description_text}")
print(f"Versions: {versions}")
print("=========================================")
except:
print('몹시 끝')
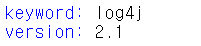
아직 초안이기 때문에
많은 기능이 구현되어 있지 않습니다.
버전을 입력한 이유는 해당 버전에 취약한 부분이 포함되는 내용만 가져오기 위해서입니다.

#버전 0.2
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
import re
import requests
# cve 검색
test = input("keyword: ")
# version 검색
version = input("version: ")
# ChromeOptions
chrome_options = Options()
#chrome_options.add_argument('--headless') # 브라우저 UI 없이 실행
chrome_options.add_argument('--disable-gpu') # GPU 사용 비활성화
# 웹 드라이버 객체 생성 + 10초 대기
driver = webdriver.Chrome(options=chrome_options)
driver.implicitly_wait(10)
# exploit-db URL
url = 'https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword='+test
driver.get(url)
#robots
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"}
try:
# 검색바 요소 찾기
time.sleep(1)
#search_box = driver.find_element(By.CSS_SELECTOR, 'input[type="search"]')
# 페이지의 HTML 콘텐츠
time.sleep(1)
page_source = driver.page_source
# BeautifulSoup을 사용하여 페이지 파싱
soup = BeautifulSoup(page_source, 'html.parser')
rows = soup.find_all('tr')
cvenum = []
#cvedes = []
for row in rows:
cve_num = row.find('a')
#cve 찾기
if cve_num and 'CVE-' in cve_num.get_text(strip=True):
print(cve_num.get_text(strip=True))
cvenum.append(cve_num.get_text(strip=True))
# 새 탭 열기
driver.execute_script("window.open('');") # 빈 탭 열기
driver.switch_to.window(driver.window_handles[-1]) # 새 탭으로 전환
url2 = f'https://www.cve.org/CVERecord?id={cve_num.get_text(strip=True)}'
driver.get(url2)
time.sleep(1)
try:
soup2 = BeautifulSoup(driver.page_source, 'html.parser')
affected_section = soup2.find('div', id='affected')
time.sleep(1)
if affected_section:
# class가 있는 부분과 없는 부분 모두 추출
affected_texts = affected_section.find_all(['span', 'p']) # span과 p 태그 모두 검색
versions = []
#버전범위검사용
tmp1=None
tmp2=None
for text in affected_texts:
versions.append(text.get_text(strip=True))
# 버전 범위 추출
for version_text in versions:
# 정규 표현식으로 숫자와 비교 연산자 추출
from_matches = re.search(r'affectedfrom\s*([\d.]+)', version_text)
before_matches = re.search(r'before\s*([\d.]+)', version_text)
if from_matches:
tmp1 = from_matches.group(1) # affected from 뒤의 숫자 추출
print(f'from: {tmp1}')
if before_matches:
tmp2 = before_matches.group(1) # before 뒤의 숫자 추출
print(f'before: {tmp2}')
else:
print(f'※ 정보없음 : {url2}')
except:
pass
print("=========================================")
# 탭 닫기
driver.close() # 현재 탭 닫기
driver.switch_to.window(driver.window_handles[0]) # 원래 탭으로 돌아가기
except:
print('몹시 끝')
추가 수정본

'Ⅰ. 프로그래밍' 카테고리의 다른 글
| CVE 관련 정보 수집 (초안) (1) | 2024.11.19 |
|---|---|
| 파이썬 프로그래밍 (이미지 실행파일) (4) | 2024.11.05 |
| exploit-db 검색 및 파싱 (0) | 2024.09.18 |
| [CodeUp] 1425 : 자리 배치 (0) | 2024.04.16 |
| [CodeUp] 1420 : 3등 찾기 (0) | 2024.04.16 |
'Ⅰ. 프로그래밍' Related Articles
more



