

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- UKPT
- 국가기록원
- webhacking
- 대외활동
- 불법유통근절
- 연구모임
- MITRE ATT&CK
- UKPT level
- 화학물질
- 국가정보원
- Los
- 국정원
- 도구모음
- 경기팀
- 파이썬
- 불법유통
- PHP
- 여행
- codeup
- suninatas
- 화학물질불법유통온라인감시단
- nurisec
- 정보보안
- 12기
- 화학물질안전원
- 웹 해킹 입문
- Service
- 기타정보
- 프로젝트
- HTML
Archives
- Today
- Total
agencies
MOBSy (웹 사이트 구축) 초안 본문
지난 시간에 이어서 colab 환경에서 웹 사이트를 구축하고자 한다.
기본 설치 명령어
!pip install flask flask-ngrok
#mobsy mobsy!2345 (ngrok)
!wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
!./ngrok authtoken 2pVOYm4ltw1s3uz2KSwrWdmncyw_82kt3McUqdiyV8WLRZQn5
!mkdir templates
!mkdir static
!mkdir instance
!mkdir uploads
!mkdir output
!pip install flask flask-mysql flask-login
!pip install flask-sqlalchemy
!pip install langgraph
!npm install -g @cyclonedx/cdxgen
!sudo apt update
!sudo apt install openjdk-21-jdk -yfrom flask_sqlalchemy import SQLAlchemy
from flask_login import UserMixin
db = SQLAlchemy()
# 사용자 테이블 정의
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True) # 고유 ID
email = db.Column(db.String(150), unique=True, nullable=False) # 이메일
username = db.Column(db.String(150), unique=True, nullable=False) # 사용자 이름
password = db.Column(db.String(150), nullable=False) # 비밀번호
SBOM 생성하는 노드
%%writefile sbom.py
import sys
import os
import uuid
import zipfile
import time
class GraphState:
def __init__(self):
self.state = {
"file_path": "",
"output_path": "", # ouput 파일 경로
"total_time": 0,
"time_spent": 0,
"status": "",
}
def add_node(self, name, func):
self.nodes.append({"name": name, "func": func})
def update_state(self, key, value):
if key in self.state:
self.state[key] = value
print(f"State updated: {key} = {value}")
else:
print(f"Warning: '{key}' is not a valid state attribute.")
class InputNode:
def __init__(self, graph_state):
self.node_id = str(uuid.uuid4())
self.graph_state = graph_state
def get_user_input(self):
print(zip_file_path)
zip_file_path = zip_file_path
#zip_file_path = input("Enter path to the zip file: ")
if not os.path.exists(zip_file_path):
raise FileNotFoundError(f"File not found: {zip_file_path}")
return zip_file_path
def extract_zip_file(self, zip_file_path, extract_to):
os.makedirs(extract_to, exist_ok=True)
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
return extract_to
def run(self):
start_time = time.time()
zip_file_path = self.get_user_input()
self.graph_state.update_state("file_path", zip_file_path)
output_path = "/content/output"
extract_to = os.path.join(output_path, "extracted")
extracted_path = self.extract_zip_file(zip_file_path, extract_to)
if extracted_path:
self.graph_state.update_state("output_path", output_path)
self.graph_state.update_state("extracted_path", extracted_path)
self.graph_state.update_state("status", "ZIP file extracted")
time_spent = int((time.time() - start_time) * 1000)
self.graph_state.update_state("time_spent", time_spent)
self.graph_state.update_state("total_time", self.graph_state.state.get("total_time", 0) + time_spent)
return extracted_path
import os
import uuid
import zipfile
import time
class InputNode:
def __init__(self, graph_state):
self.graph_state = graph_state
def _clean_output_directory(self):
"""
Deletes files within the 'AnA', 'SBOM', 'TEMP', and 'extracted' directories
and any files directly under '/content/output', while keeping the directory structure intact.
"""
base_output_path = "/content/output"
folders_to_clean = ["AnA", "SBOM", "TEMP", "extracted"]
# Clean specified folders
for folder in folders_to_clean:
folder_path = os.path.join(base_output_path, folder)
if os.path.exists(folder_path):
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path) # Remove files or symbolic links
elif os.path.isdir(file_path):
shutil.rmtree(file_path) # Remove directories
except Exception as e:
print(f"Failed to delete {file_path}. Reason: {e}")
# Remove files directly under '/content/output'
for filename in os.listdir(base_output_path):
file_path = os.path.join(base_output_path, filename)
try:
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
except Exception as e:
print(f"Failed to delete {file_path}. Reason: {e}")
def run(self):
"""
Main execution of the InputNode:
- Cleans up old files.
- Prompts user for the ZIP file path.
- Extracts the contents of the ZIP file.
"""
# Step 1: Clean previous output files
self._clean_output_directory()
# Step 2: Prompt for ZIP file path
#zip_file_path = input("Enter path to the zip file: ").strip()
if not os.path.exists(zip_file_path):
raise FileNotFoundError(f"The file {zip_file_path} does not exist.")
print(zip_file_path)
self.graph_state.update_state("file_path", zip_file_path)
# Step 3: Create output path
output_path = "/content/output"
os.makedirs(output_path, exist_ok=True)
self.graph_state.update_state("output_path", output_path)
# Step 4: Extract ZIP file
extracted_path = os.path.join(output_path, "extracted")
os.makedirs(extracted_path, exist_ok=True)
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall(extracted_path)
self.graph_state.update_state("status", "ZIP file extracted")
print(f"Files extracted to: {extracted_path}")
import uuid
import os
import csv
class CFileExtractNode:
def __init__(self, graph_state):
self.node_id = str(uuid.uuid4()) # Unique node ID
self.graph_state = graph_state
# Create a CSV file from the .c files without code normalization
def create_c_files_csv(self, files, output_csv):
if not files:
print("No .c files found.")
self.graph_state.update_state("status", "No .c files found for CSV creation.")
return
with open(output_csv, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['file_name', 'original_code']) # Original code, no normalization
for file_name, code in files:
writer.writerow([file_name, code])
print(f".c files CSV created: {output_csv}")
self.graph_state.update_state("status", "C files extracted and saved")
# Process .c files: Extract and save to CSV without normalization
def process_c_files(self, project_dir, output_csv):
c_files = []
for root, dirs, files in os.walk(project_dir):
for file in files:
if file.endswith('.c'):
file_path = os.path.join(root, file)
with open(file_path, 'r', encoding='utf-8') as f:
code = f.read()
c_files.append((file, code)) # Append without normalization
print(f"Processed .c file: {file_path}")
self.create_c_files_csv(c_files, output_csv)
# Node execution function
def run(self):
# Get extracted path from the graph state
output_path = self.graph_state.state.get("output_path")
if not output_path:
print("Output path not found in the graph state.")
return None
# Define the extracted directory and CSV output path
extracted_path = os.path.join(output_path, "extracted")
os.makedirs(extracted_path, exist_ok=True) # Ensure extracted directory exists
output_csv = os.path.join(extracted_path, "c_files.csv")
# Process .c files in the extracted path and save to CSV
self.process_c_files(extracted_path, output_csv)
# Update state to reflect completion
self.graph_state.update_state("status", "C files extracted and saved")
return output_csv
#sbom 생성
import os
import json
import csv
import uuid
import subprocess
import pandas as pd
import hashlib
import shutil
class SBOMGenerateNode:
def __init__(self, graph_state):
self.node_id = str(uuid.uuid4()) # Unique node ID
self.graph_state = graph_state
# Generate SBOM and save to JSON file
def generate_sbom_from_project_dir(self, project_dir):
self.graph_state.update_state("status", "Generating SBOM from project directory")
# Check if the directory contains any .c files
c_file_exists = any(file.endswith('.c') for root, dirs, files in os.walk(project_dir) for file in files)
if not c_file_exists:
print("No .c files found in the project directory.")
self.graph_state.update_state("status", "No .c files found for SBOM generation")
return None
try:
output_path = self.graph_state.state.get("output_path")
sbom_path = os.path.join(self.graph_state.state.get("output_path"), "SBOM")
os.makedirs(sbom_path, exist_ok=True)
# sbom_output_file = os.path.join(sbom_path, "sbom.json")
# oss_csv_output_file = os.path.join(sbom_path, "oss_csv.csv") # oss_csv_file 경로 수정
# usages_json_file = os.path.join(sbom_path, "usages.slices.json")
# #usages_csv_file = os.path.join(sbom_path, f"{os.path.basename(project_dir)}_usages.csv")
# usages_csv_file = os.path.join(sbom_path, "usages.slices.csv")
sbom_output_file = os.path.join(sbom_path, "sbom.json")
oss_csv_output_file = os.path.join(sbom_path, "oss_csv.csv")
usages_json_file = os.path.join(output_path, "usages.slices.json") # 수정된 경로
usages_csv_file = os.path.join(sbom_path, "usages.slices.csv")
# Run cdxgen to generate SBOM JSON
subprocess.run(["cdxgen", "-t", "c", "-o", sbom_output_file, project_dir], check=True)
print(f"SBOM generated at {sbom_output_file}")
# Convert the SBOM JSON to CSV for OSS information
self.convert_sbom_to_csv(sbom_output_file, oss_csv_output_file)
# 파일 이동
original_usages_json_file = "/content/usages.slices.json"
# original_usages_json_file = "/content/usages.slices.json"
if os.path.exists(original_usages_json_file):
shutil.move(original_usages_json_file, usages_json_file)
print(f"Moved usages.slices.json to {usages_json_file}")
# Convert usages JSON to CSV if usages.slices.json exists
if os.path.exists(usages_json_file):
self.convert_usages_json_to_csv(usages_json_file, usages_csv_file)
print("usages.slices.json converted to CSV")
else:
print("usages.slices.json not found")
self.graph_state.update_state("status", "usages.slices.json not found")
return None
# Update state with the SBOM and CSV file paths
self.graph_state.update_state("status", "SBOM, OSS CSV, and Usages CSV generated successfully")
return sbom_output_file, oss_csv_output_file, usages_csv_file # oss_csv_file 포함하여 반환
except Exception as e:
print(f"Error during SBOM generation: {e}")
self.graph_state.update_state("status", f"Failed during SBOM generation: {e}")
return None
# Convert SBOM JSON to CSV with OSS information
def convert_sbom_to_csv(self, json_file, csv_file):
all_data = []
try:
with open(json_file, encoding='utf-8') as f:
data = json.load(f)
components = data.get('components', [])
for component in components:
properties = {prop['name']: prop['value'] for prop in component.get('properties', [])}
all_data.append({
'name': component.get('name'),
'Version': component.get('version'),
'BOM Ref': component.get('bom-ref'),
'Type': component.get('type'),
'PURL': component.get('purl'),
})
df = pd.DataFrame(all_data)
df.to_csv(csv_file, index=False)
print(f"OSS information CSV file created: {csv_file}")
except Exception as e:
print(f"Error during CSV conversion: {e}")
self.graph_state.update_state("status", f"Error during CSV conversion: {e}")
# Convert usages.slices.json to CSV with additional information
def convert_usages_json_to_csv(self, json_file, csv_file):
rows = []
try:
if not os.path.exists(json_file):
print(f"JSON file not found: {json_file}")
self.graph_state.update_state("status", f"JSON file not found: {json_file}")
return
with open(json_file, 'r', encoding='utf-8') as f:
data = json.load(f)
for obj in data['objectSlices']:
full_name = obj.get('fullName', '')
signature = obj.get('signature', '')
file_name = obj.get('fileName', '')
line_number = obj.get('lineNumber', '')
column_number = obj.get('columnNumber', '')
for usage in obj.get('usages', []):
target_obj = usage.get('targetObj', {})
usage_name = target_obj.get('name', '')
usage_type_fullname = target_obj.get('typeFullName', '')
usage_line_number = target_obj.get('lineNumber', '')
usage_column_number = target_obj.get('columnNumber', '')
invoked_calls = usage.get('invokedCalls', [])
invoked_calls_info = ', '.join([call.get('name', '') for call in invoked_calls])
arg_to_calls = usage.get('argToCalls', [])
arg_to_calls_info = ', '.join([arg.get('name', '') for arg in arg_to_calls])
# Generate MD5 hash for usage name
usage_name_hash = hashlib.md5(usage_name.encode()).hexdigest() if usage_name else ''
rows.append({
"Function Full Name": full_name,
"Signature": signature,
"Defined File Name": file_name,
"Defined Line Number": line_number,
"Defined Column Number": column_number,
"Usage Name": usage_name,
"Hash": usage_name_hash,
"Usage Type Full Name": usage_type_fullname,
"Usage Line Number": usage_line_number,
"Usage Column Number": usage_column_number,
"Invoked Calls": invoked_calls_info,
"Argument to Calls": arg_to_calls_info
})
df = pd.DataFrame(rows)
df.to_csv(csv_file, index=False)
print(f"Usages information CSV file created: {csv_file}")
except Exception as e:
print(f"Error during Usages JSON to CSV conversion: {e}")
self.graph_state.update_state("status", f"Error during Usages CSV conversion: {e}")
# Node execution function
def run(self):
start_time = time.time()
# Retrieve extracted path and project name
output_path = self.graph_state.state.get("output_path")
extracted_path = os.path.join(output_path, "extracted")
project_dir = extracted_path
print(f"Output path: {output_path}")
print(f"Extracted path: {extracted_path}")
# print(f"Project name from ZIP: {project_name}")
print(f"Constructed project directory path: {project_dir}")
if not os.path.exists(project_dir):
print("Project directory not found.")
return None
result = self.generate_sbom_from_project_dir(project_dir)
time_spent = int((time.time() - start_time) * 1000) # Convert to milliseconds
self.graph_state.update_state("time_spent", time_spent)
self.graph_state.update_state("total_time", self.graph_state.state.get("total_time", 0) + time_spent)
return result
def main(zip_file_path):
graph_state = GraphState()
input_node = InputNode(graph_state)
extracted_path = input_node.run() # ZIP 파일 처리
c_file_node = CFileExtractNode(graph_state)
c_file_node.run() # .c 파일 처리 및 CSV 생성
sbom_node = SBOMGenerateNode(graph_state)
result = sbom_node.run() # SBOM 생성
return result
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python sbom.py <zip_file_path>")
sys.exit(1)
zip_file_path = sys.argv[1]
main(zip_file_path)
플라스크
# Flask 코드 작성
from flask import Flask, render_template
from flask import request, redirect, url_for, session, jsonify, send_from_directory
from flask_ngrok import run_with_ngrok
import os
import zipfile
import subprocess
app = Flask(__name__)
run_with_ngrok(app) # ngrok을 사용하여 외부에서 접근 가능하게 만듦
# 업로드된 파일 저장 경로
UPLOAD_FOLDER = './uploads'
os.makedirs(UPLOAD_FOLDER, exist_ok=True) # 폴더 생성
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['OUTPUT_FOLDER_SBOM'] = 'output/SBOM'
# ZIP 파일 업로드 및 처리
@app.route('/upload', methods=['POST'])
def upload_zip():
if 'file' not in request.files:
return jsonify({'message': 'No file part'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'message': 'No selected file'}), 400
# ZIP 파일만 허용
if not file.filename.endswith('.zip'):
return jsonify({'message': 'Only ZIP files are allowed'}), 400
# 파일 저장
zip_path = os.path.join(app.config['UPLOAD_FOLDER'], file.filename)
file.save(zip_path)
try:
# sbom.py 스크립트 실행
result = subprocess.run(['python', 'sbom.py', zip_path], capture_output=True, text=True, check=True)
# 파일 생성 경로 가정
generated_file = os.path.join(app.config['OUTPUT_FOLDER_SBOM'], 'sbom.json')
if os.path.exists(generated_file):
file_url = f'/output/sbom/sbom.json' # Flask에서 다운로드 URL
return jsonify({'output': result.stdout, 'file_url': file_url}), 200
else:
return jsonify({'message': 'SBOM 파일 생성 실패'}), 500
except subprocess.CalledProcessError as e:
return jsonify({'message': 'SBOM 생성 중 오류 발생', 'error': e.stderr}), 500
@app.route('/output/sbom/<filename>', methods=['GET'])
def download_file(filename):
"""생성된 파일 다운로드"""
directory = app.config['OUTPUT_FOLDER_SBOM']
try:
return send_from_directory(directory, filename, as_attachment=True)
except FileNotFoundError:
return jsonify({'message': '파일을 찾을 수 없습니다.'}), 404
@app.route('/')
def index():
"<h1>/start로 가세요</h1>"
return render_template('start.html') # 책소개페이지
@app.route("/start")
def start():
return render_template("start.html") # templates 폴더의 index.html 파일 로드
@app.route("/dashboard")
def dashboard():
if 'username' not in session:
# 로그인하지 않은 경우 리디렉션
return redirect(url_for('start'))
username = session['username'] # 세션에서 사용자 이름 가져오기
return render_template('dashboard.html', username=username)
app.secret_key = 'your_secret_key'
# SQLite 데이터베이스 설정
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///users.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db.init_app(app)
# 데이터베이스 생성
with app.app_context():
db.create_all()
@app.route('/signup', methods=['POST'])
def signup():
email = request.form.get('email')
username = request.form.get('username')
password = request.form.get('password')
# 유효성 검사
if not email or not username or not password:
return jsonify({"message": "모든 필드를 입력하세요."}), 400
# 중복 사용자 확인
if User.query.filter_by(email=email).first():
return jsonify({"message": "이미 존재하는 이메일입니다."}), 400
if User.query.filter_by(username=username).first():
return jsonify({"message": "이미 존재하는 사용자 이름입니다."}), 400
# 사용자 저장
new_user = User(email=email, username=username, password=password)
db.session.add(new_user)
db.session.commit()
return jsonify({"message": "회원가입 성공!"}), 200
@app.route('/login', methods=['POST'])
def login():
username = request.form.get('username')
password = request.form.get('password')
# 사용자 확인
user = User.query.filter_by(username=username, password=password).first()
if not user:
return jsonify({"success": False, "message": "잘못된 사용자 이름 또는 비밀번호입니다."}), 401
# 로그인 성공
session['username'] = user.username # 세션에 사용자 이름 저장
return jsonify({"success": True, "message": "로그인 성공!"}), 200
if __name__ == "__main__":
app.run()
로그인을 하고 난 뒤 sbom을 생성해보자!
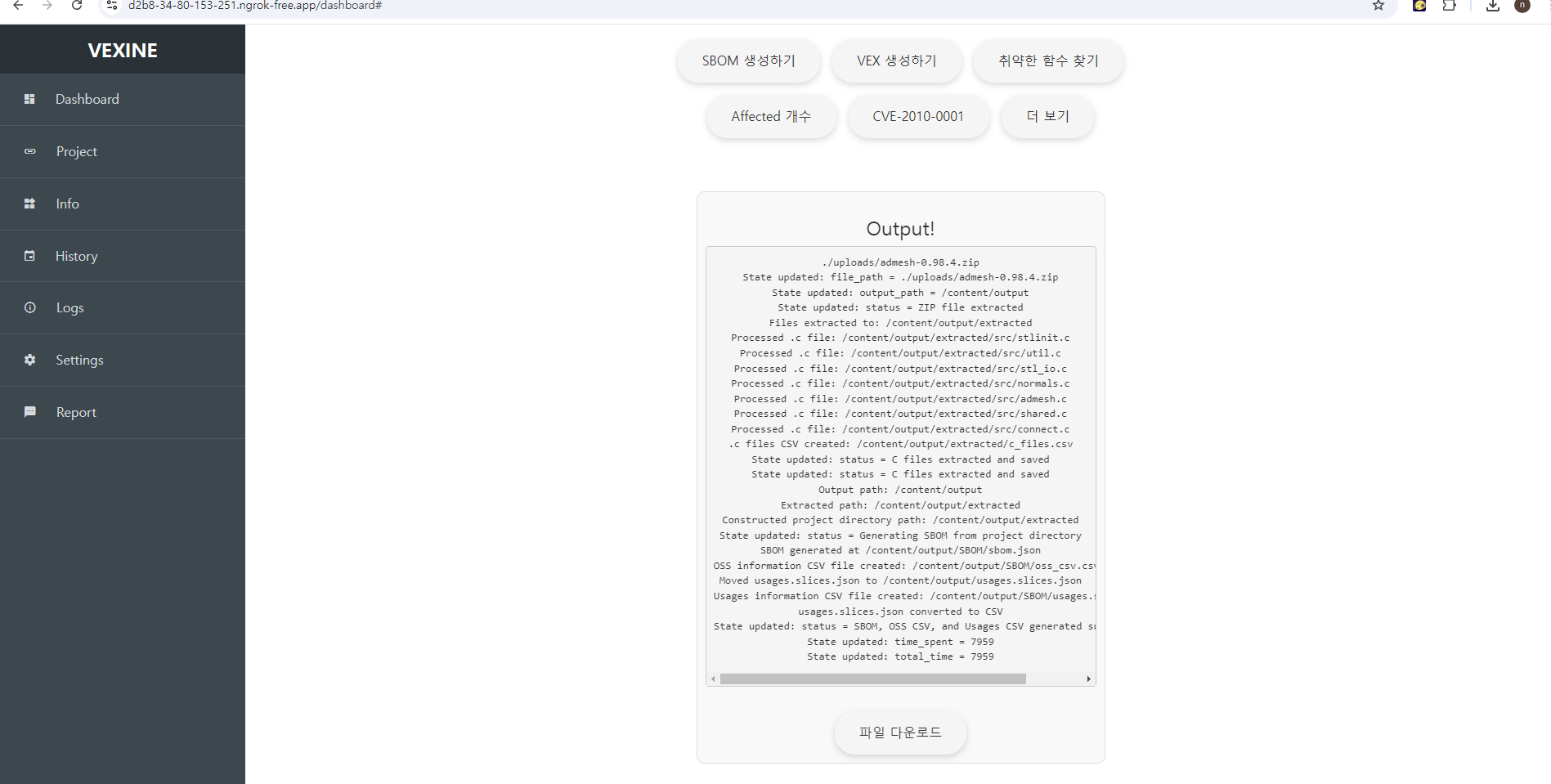
이렇게 파일 다운로드 버튼이 생긴다!
누르면!

'Ⅴ. 프로젝트' 카테고리의 다른 글
| [BoB 시연영상 : VEX 및 SBOM 생성] (초안) (0) | 2024.12.20 |
|---|---|
| BoB 프로젝트(초안-3) : backup용 (0) | 2024.12.17 |
| BoB 프로젝트(초안-2) : backup용 (0) | 2024.12.16 |
| BoB 프로젝트(초안) : backup용 (0) | 2024.12.14 |
| MOBSy (웹 사이트 구축) 초안(두번째) (1) | 2024.11.30 |
'Ⅴ. 프로젝트' Related Articles
more
