
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 여행
- UKPT
- Service
- 국가기록원
- UKPT level
- 경기팀
- 화학물질안전원
- 국가정보원
- nurisec
- codeup
- webhacking
- 연구모임
- 프로젝트
- 불법유통근절
- 국정원
- HTML
- suninatas
- 웹 해킹 입문
- 파이썬
- 화학물질불법유통온라인감시단
- 화학물질
- 12기
- 도구모음
- Los
- 대외활동
- PHP
- 기타정보
- MITRE ATT&CK
- 불법유통
- 정보보안
Archives
- Today
- Total
agencies
backward slicing (추상화:joern) + 전체 소스코드 추상화 본문
이번시간에는
backward slicing 으로 실제 취약한 함수의 흐름을 파악할 수 있도록 joern을 이용한 흐름 추적을 통해
나온 결과물을 추상화 하고
전체 소스코드를 추상화 한 것과 비교를 해보고자 합니다.
import subprocess
import json
import hashlib
import csv
from pycparser import c_parser, c_ast
import re
import os
# Joern 파일 경로 및 함수 이름
file_name = "/content/connect.c"
func_name = "stl_remove_degenerate"
csv_file_name = "/content/backward-db.csv"
class Abstractor(c_ast.NodeVisitor):
def __init__(self):
self.param_map = {}
self.var_map = {}
self.func_names = set()
def visit_FuncDef(self, node):
self.func_names.add(node.decl.name)
if node.decl.type.args:
for param in node.decl.type.args.params:
self.param_map[param.name] = "param"
self.generic_visit(node)
def visit_Decl(self, node):
if node.name not in self.param_map and node.name not in self.func_names:
if node.name not in self.var_map:
self.var_map[node.name] = "var"
self.generic_visit(node)
def abstract_code(self, code):
abstracted_code = code
for original, abstracted in self.param_map.items():
abstracted_code = self._replace_safe(abstracted_code, original, abstracted)
for original, abstracted in self.var_map.items():
abstracted_code = self._replace_safe(abstracted_code, original, abstracted)
return abstracted_code
def _replace_safe(self, code, old, new):
pattern = r'\b' + re.escape(old) + r'\b'
return re.sub(pattern, new, code)
def remove_comments_and_preprocessor(code):
"""
주석 및 전처리 지시문 제거 후 개행을 유지합니다.
"""
# 라인 주석 제거
code = re.sub(r'//.*', '', code)
# 블록 주석 제거
code = re.sub(r'/\*.*?\*/', lambda match: '\n' * match.group(0).count('\n'), code, flags=re.S)
# 전처리 지시문(#include 등) 제거
code = re.sub(r'#.*', '', code)
return code
def process_code(input_code):
"""
주어진 C 코드를 추상화하고 결과를 반환합니다.
"""
# 주석 및 전처리 지시문 제거 후 개행 유지
code_without_comments = remove_comments_and_preprocessor(input_code)
# 파싱 및 추상화
parser = c_parser.CParser()
abstractor = Abstractor()
try:
ast = parser.parse(code_without_comments)
abstractor.visit(ast)
abstracted_code = abstractor.abstract_code(code_without_comments)
return abstracted_code
except Exception as e:
print(f"코드 파싱 오류: {e}")
return code_without_comments # 오류 발생 시 원본 반환
# 사용자 코드 읽기
with open(file_name, "r", encoding='utf-8') as user_code_file:
user_code = user_code_file.read()
# 코드 추상화
abstracted_code = process_code(user_code)
# 추상화된 코드 저장
output_file = file_name.split('.c')[0] + '_tmp.c'
with open(output_file, "w", encoding="utf-8") as file:
file.write(abstracted_code)
print(f"추상화된 코드가 {output_file}에 저장되었습니다.")
# Joern 스크립트 생성
joern_script_content = f"""
importCode("{file_name}")
// 이미 추적한 줄 번호를 저장하여 중복 방지
val visitedLines = scala.collection.mutable.Set[Int]()
val result = scala.collection.mutable.ListBuffer[Int]()
// 특정 변수의 backward slicing 수행
def traceBackwardSlicing(variableName: String, methodName: String): Unit = {{
println("=== 함수 '" + methodName + "'의 변수 '" + variableName + "' backward slicing ===")
// 변수 사용 위치 추적 (methodName 내부로 제한)
val variableUses = cpg.identifier.nameExact(variableName).where(_.method.nameExact(methodName))
variableUses.foreach {{ useNode =>
// 데이터 의존성 추적 (ddgIn)
val dataDependencies = useNode.ddgIn
dataDependencies.foreach {{ node =>
val lineNumber = node.lineNumber.getOrElse(-1)
val nodeCode = node.code
if (!visitedLines.contains(lineNumber) && lineNumber != -1 &&
nodeCode != null) {{
visitedLines.add(lineNumber)
result += lineNumber
println(s"데이터 의존성 있는 코드: ${{node.code}} (줄 번호: $lineNumber)")
}}
}}
// 변수 사용이 포함된 모든 호출을 추적
val callsUsingVariable = useNode.inCall
callsUsingVariable.foreach {{ callNode =>
val lineNumber = callNode.lineNumber.getOrElse(-1)
val nodeCode = callNode.code
if (!visitedLines.contains(lineNumber) && lineNumber != -1 &&
nodeCode != null && nodeCode.contains(variableName)) {{
visitedLines.add(lineNumber)
result += lineNumber
println(s"변수를 사용하는 호출: ${{callNode.code}} (줄 번호: $lineNumber)")
}}
}}
// 제어 흐름 상의 관련성 추적 (cfgIn)
val controlDependencies = useNode.cfgIn
controlDependencies.foreach {{ node =>
val lineNumber = node.lineNumber.getOrElse(-1)
val nodeCode = node.code
if (!visitedLines.contains(lineNumber) && lineNumber != -1 &&
nodeCode != null && nodeCode.contains(variableName)) {{
visitedLines.add(lineNumber)
result += lineNumber
println(s"제어 흐름 관련 코드: ${{node.code}} (줄 번호: $lineNumber)")
}}
}}
}}
}}
// Main 함수 작업
val callsInMain = cpg.method.name("main").call
val funcCalls = callsInMain.name("{func_name}")
if (!funcCalls.isEmpty) {{
println("Main 함수에서 취약한 함수 발견!")
funcCalls.argument.foreach {{ arg =>
val variableName = arg.code
println(s"파라미터: ${{variableName}}")
traceBackwardSlicing(variableName, "main")
}}
// 함수 호출 추적
funcCalls.foreach {{ callNode =>
callNode.inAssignment.foreach {{ assignNode =>
val assignedVariable = assignNode.target.code
println(s"함수 결과가 변수 '${{assignedVariable}}'에 할당됨")
traceBackwardSlicing(assignedVariable, "main")
}}
}}
}}
// 지역 함수 작업 (vulnerable_function)
val methods = cpg.method.name("{func_name}")
if (methods.size > 0) {{
methods.foreach {{ method =>
println(s"=== 함수 '${{method.name}}' 작업 ===")
method.parameter.foreach {{ param =>
val paramName = param.name
println(s"파라미터: ${{paramName}}")
traceBackwardSlicing(paramName, method.name)
}}
// 함수 내 데이터 의존성 추적 (strcpy와 관련된 변수만 포함)
method.call.name("strcpy").argument.foreach {{ arg =>
val variableName = arg.code
println(s"관련 변수: ${{variableName}}")
traceBackwardSlicing(variableName, method.name)
}}
}}
}}
// JSON 형식으로 결과 출력
println(ujson.write(result.toList))
"""
# Joern 스크립트 저장
script_path = "/content/trace.sc"
with open(script_path, "w") as script_file:
script_file.write(joern_script_content)
# Joern 실행
result = subprocess.run(
["/content/joern-cli/joern", "--script", script_path],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True
)
# Joern 실행 결과 출력 및 CSV 생성
if result.returncode == 0:
print("Joern 실행 성공!")
output = result.stdout.strip()
print("=== 분석 결과 ===")
print(output)
try:
# JSON 결과 추출 및 Python 변수로 저장
lines = json.loads(output.splitlines()[-1]) # 마지막 JSON 출력 파싱
lines.sort() # 리스트를 오름차순으로 정렬
print(f"Python 변수로 저장된 라인 번호 (오름차순): {lines}")
# 파일 읽어서 특정 라인 번호의 소스 코드 추출
with open(file_name, "r") as file:
file_content = file.readlines() # 원본 파일 내용
with open(output_file, "r") as tmp_file:
tmp_file_content = tmp_file.readlines() # 추상화된 파일 내용
print("=== 특정 라인의 소스 코드 ===")
rows = [] # CSV에 저장할 데이터를 담을 리스트
for line_number in lines:
if 0 < line_number <= len(file_content): # 유효한 라인 번호인지 확인
origin_code = file_content[line_number - 1].strip() # 원본 코드
abs_code = tmp_file_content[line_number - 1].strip() if line_number <= len(tmp_file_content) else "" # 추상화된 코드
# 주석이나 빈 줄 확인
is_comment = re.match(r'^\s*(#|//|/\*|\*|\*/)', origin_code) # 주석 확인
is_empty = not origin_code.strip() # 빈 줄 확인
if is_comment or is_empty:
continue # 주석 또는 빈 줄은 무시
# 현재 라인 번호를 기반으로 데이터 구성
print(f"{line_number}: origin: {origin_code}, abs_code: {abs_code}")
rows.append({
"file_name": file_name,
"lines": line_number,
"func_name": func_name,
"origin": origin_code,
"abs_code": abs_code
})
# 기존 CSV 읽어서 중복 확인
existing_hashes = set()
if os.path.exists(csv_file_name):
with open(csv_file_name, "r", encoding="utf-8") as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
if "hash" in row: # 해시 값이 있는지 확인
existing_hashes.add(row["hash"])
# CSV 파일 업데이트
with open(csv_file_name, "a", newline="", encoding="utf-8") as csv_file: # 'a' 모드로 파일 열기
csv_writer = csv.DictWriter(csv_file, fieldnames=["file_name", "lines", "func_name", "origin", "abs_code", "hash"])
# 헤더 작성 (처음 생성될 때만 추가)
if os.stat(csv_file_name).st_size == 0:
csv_writer.writeheader()
for row in rows:
# 추상화된 코드(abs_code)를 정규화한 후 해시 생성
normalized_abs_code = re.sub(r'\s+', '', row["abs_code"])
hash_value = hashlib.sha256(normalized_abs_code.encode("utf-8")).hexdigest()
if hash_value not in existing_hashes: # 중복 확인
csv_writer.writerow({
"file_name": row["file_name"],
"lines": row["lines"], # 원본 코드의 라인 번호
"func_name": row["func_name"],
"origin": row["origin"],
"abs_code": normalized_abs_code,
"hash": hash_value
})
existing_hashes.add(hash_value) # 새로운 해시 추가
print(f"CSV 파일 업데이트 완료: {csv_file_name}")
except json.JSONDecodeError as e:
print("JSON 디코딩 오류:", e)
else:
print("Joern 실행 실패!")
print("=== 오류 메시지 ===")
print(result.stderr.strip())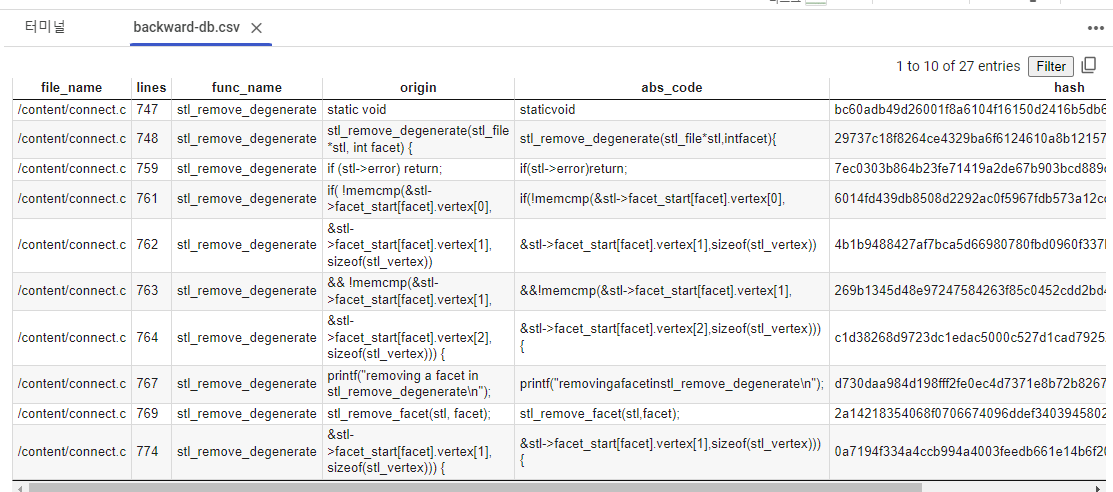
import hashlib
import csv
from pycparser import c_parser, c_ast
import re
import os
file_name="test.c"
class Abstractor(c_ast.NodeVisitor):
def __init__(self):
self.param_map = {}
self.var_map = {}
self.func_names = set()
def visit_FuncDef(self, node):
self.func_names.add(node.decl.name)
if node.decl.type.args:
for param in node.decl.type.args.params:
self.param_map[param.name] = "param"
self.generic_visit(node)
def visit_Decl(self, node):
if node.name not in self.param_map and node.name not in self.func_names:
if node.name not in self.var_map:
self.var_map[node.name] = "var"
self.generic_visit(node)
def abstract_code(self, code):
abstracted_code = code
for original, abstracted in self.param_map.items():
abstracted_code = self._replace_safe(abstracted_code, original, abstracted)
for original, abstracted in self.var_map.items():
abstracted_code = self._replace_safe(abstracted_code, original, abstracted)
return abstracted_code
def _replace_safe(self, code, old, new):
pattern = r'\b' + re.escape(old) + r'\b'
return re.sub(pattern, new, code)
def remove_comments_and_preprocessor(code):
"""
주석 및 전처리 지시문 제거 후 개행을 유지합니다.
"""
# 라인 주석 제거
code = re.sub(r'//.*', '', code)
# 블록 주석 제거
code = re.sub(r'/\*.*?\*/', lambda match: '\n' * match.group(0).count('\n'), code, flags=re.S)
# 전처리 지시문(#include 등) 제거
code = re.sub(r'#.*', '', code)
return code
def process_code(input_code):
"""
주어진 C 코드를 추상화하고 결과를 반환합니다.
"""
# 주석 및 전처리 지시문 제거 후 개행 유지
code_without_comments = remove_comments_and_preprocessor(input_code)
# 파싱 및 추상화
parser = c_parser.CParser()
abstractor = Abstractor()
try:
ast = parser.parse(code_without_comments)
abstractor.visit(ast)
abstracted_code = abstractor.abstract_code(code_without_comments)
return abstracted_code
except Exception as e:
print(f"코드 파싱 오류: {e}")
return code_without_comments # 오류 발생 시 원본 반환
# 사용자 코드 읽기
with open(file_name, "r", encoding='utf-8') as user_code_file:
user_code = user_code_file.read()
# 코드 추상화
abstracted_code = process_code(user_code)
lines = abstracted_code.splitlines() # 추상화된 코드를 줄 단위로 나누기
stripped_lines = [re.sub(r'\s+', '', line) for line in lines] # 각 줄의 공백 제거
processed_code = '\n'.join(stripped_lines) # 공백 제거된 코드 다시 결합
# 추상화된 코드 저장
output_file = file_name.split('.c')[0] + '_tmp.c'
with open(output_file, "w", encoding="utf-8") as file:
file.write(processed_code)
print(f"추상화된 코드가 {output_file}에 저장되었습니다.")
# CSV 파일 저장
csv_file_name = "abstracted_code.csv"
rows = []
# 원본 및 추상화된 코드를 라인 단위로 비교하여 저장
original_lines = user_code.splitlines()
abstracted_lines = processed_code.splitlines()
for line_number, (original, abstracted) in enumerate(zip(original_lines, abstracted_lines), start=1):
# 주석이나 빈 줄 확인
is_comment = re.match(r'^\s*(#|//|/\*|\*|\*/)', original.strip()) # 한 줄 주석, 블록 주석, 빈 주석 등 확인
is_empty = not original.strip() # 빈 줄인지 확인
if is_comment or is_empty:
continue # 주석 또는 빈 줄은 무시
# CSV에 저장할 행 구성
row = {
"file_name": file_name,
"lines": line_number, # 실제 원본 코드의 라인 번호
"origin": original.strip(),
"abs_code": abstracted.strip(),
"hash": hashlib.sha256(abstracted.strip().encode("utf-8")).hexdigest()
}
rows.append(row)
# CSV 파일 업데이트
with open(csv_file_name, "a", newline="", encoding="utf-8") as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=["file_name", "lines", "origin", "abs_code", "hash"])
# 헤더 작성 (파일이 비어 있을 경우에만 추가)
if os.stat(csv_file_name).st_size == 0:
csv_writer.writeheader()
# 중복 확인 없이 바로 쓰기
for row in rows:
csv_writer.writerow(row)
print(f"추상화된 코드 및 해시가 {csv_file_name}에 저장되었습니다.")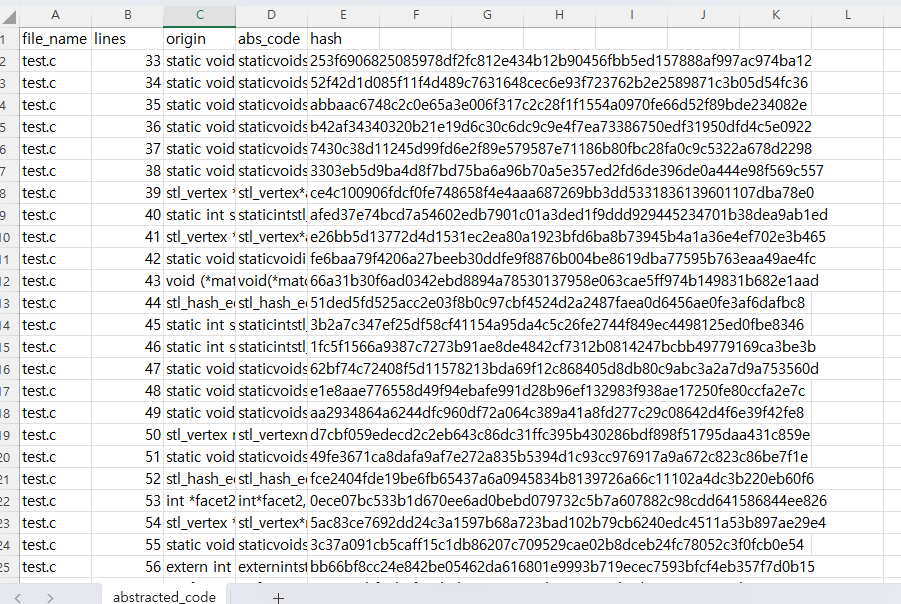
아쉽게 1줄이 밀린다...
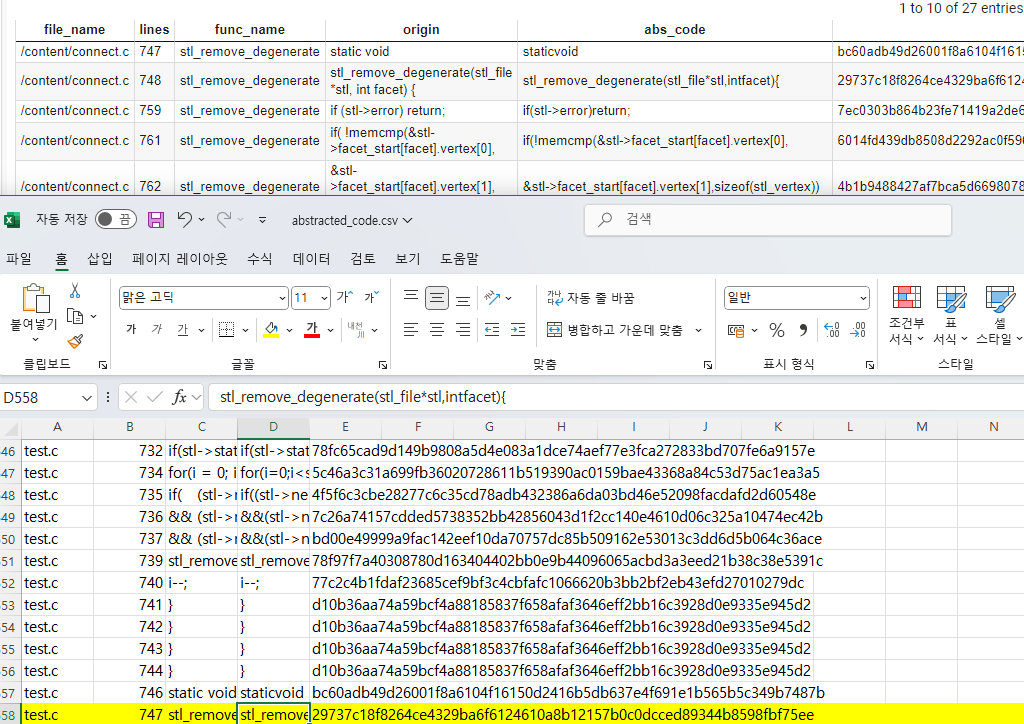
=> 아마도 추상화가 진행되지 않으면 -1 만큼의 오차가 발생되고
추상화가 정상적으로 동작하면 정확한 라인이 되는 것 같다..
'Ⅳ. 기타' 카테고리의 다른 글
| 파일 탐색기 (응답 없음) 해결 방법 (0) | 2024.11.30 |
|---|---|
| colab 환경에서 웹 사이트 구축해보기 (flask / ngrok) 및 python 코드 실행해보기! (0) | 2024.11.29 |
| joern 을 통한 취약한 함수에 들어가는 파라미터 backward slicing (0) | 2024.11.27 |
| vul 폴더에 있는 patch 파일을 통해 취약한 코드 있는 여부 확인해보기 (0) | 2024.11.25 |
| CVE database (구축) : 고도화 (combined -> ) (2) | 2024.11.25 |
'Ⅳ. 기타' Related Articles
more



